Overlapping AllGather GEMM on AMD GPU
This script demonstrates the implementations allgather-gemm intra node with computational communication overlap using Triton-distrbuted.
In this tutorial, you will write a simple fused AllGather and Gemm using Triton-distributed.
In doing so, you will learn about:
How to finely partition communication (producers) and computation (consumers) and overlap them.
Intra node communication on AMD GPUs.
# To run this tutorial
bash ./scripts/launch_amd.sh tutorials/09-AMD-overlapping-allgather-gemm.py
Background
The typical implementation of AG + Gemm is sequential, and communication and computation cannot be parallelized. As shown below:
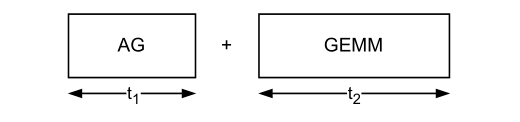
The total time consumption is t1 + t2.
Notice that when the shape of GEMM is relatively large, it is always tiled into small blocks for computation on heterogeneous accelerators. This means that there are always some tiles computed first and some computed later. Therefore, we can first transfer the data that is first relied on the GEMM computation during AG, so that the GEMM computation and the AG communication can be overlapped, improving the overall MFU. As shown below, both communication and computation are divided into 4 blocks, and the blocks with the same number have dependencies:
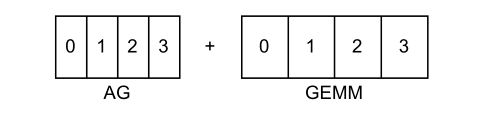
Then the effect of the overlap is as follows:

Under the ideal computation-to-memory access ratio, we can hide the communication time of blocks 1, 2, and 3 in the GEMM computation time overhead. Fortunately, there is always a part of the AG communication that is local. Local communication can be omitted or has very low overhead. If the communication of block 0 only occurs locally, then the GEMM waiting for the communication of block 0 always has almost no overhead.
Assume that the shapes of matrices A and B in GEMM are [M, K] and [K, N] respectively. We can partition both communication and computation along the M-axis into several chunks. Communication is carried out on a per-chunk basis, and each tile of GEMM needs to wait for the data on the chunks it depends on to arrive. We can use signals to build a producer-consumer dependency model. That is, GEMM acts as the consumer and waits for the signals that the current tile’s computation depends on, while AG acts as the producer and sets the signals after the data transfer is completed. For example, assume that the size of M is 1024, the size of each chunk is 128, and the BLOCK_SIZE_M of GEMM is 256. Then each tile of GEMM needs to wait for the signals of two chunks to arrive.
Kernel
The differences from the gemm-only kernel are: (1) Each tile needs to wait for the arrival of the dependent signals before computation; (2) Swizzling is performed on the order of the chunks for AG communication.
@triton_dist.jit
def consumer_gemm_persistent_kernel(
A,
localA,
B,
C,
M,
N,
K,
stride_am,
stride_ak,
stride_bk,
stride_bn,
stride_cm,
stride_cn,
rank,
world_size,
barrier_ptr, # signals
BLOCK_SIZE_M: tl.constexpr,
BLOCK_SIZE_N: tl.constexpr,
BLOCK_SIZE_K: tl.constexpr,
GROUP_SIZE_M: tl.constexpr,
M_PER_CHUNK: tl.constexpr,
NUM_SMS: tl.constexpr,
NUM_XCDS: tl.constexpr,
EVEN_K: tl.constexpr,
):
pid = tl.program_id(0)
if NUM_XCDS != 1:
pid = (pid % NUM_XCDS) * (NUM_SMS // NUM_XCDS) + (pid // NUM_XCDS)
num_pid_m = tl.cdiv(M, BLOCK_SIZE_M)
num_pid_n = tl.cdiv(N, BLOCK_SIZE_N)
total_tiles = num_pid_m * num_pid_n
tl.assume(stride_am > 0)
tl.assume(stride_ak > 0)
tl.assume(stride_bn > 0)
tl.assume(stride_bk > 0)
tl.assume(stride_cm > 0)
tl.assume(stride_cn > 0)
M_per_rank = M // world_size
pid_m_per_rank = tl.cdiv(M_per_rank, BLOCK_SIZE_M)
acc_dtype = tl.float32 if C.type.element_ty != tl.int8 else tl.int32
for tile_id in range(pid, total_tiles, NUM_SMS):
num_pid_in_group = GROUP_SIZE_M * num_pid_n
group_id = tile_id // num_pid_in_group
first_pid_m = group_id * GROUP_SIZE_M
group_size_m = min(num_pid_m - first_pid_m, GROUP_SIZE_M)
pid_m = first_pid_m + ((tile_id % num_pid_in_group) % group_size_m)
pid_n = (tile_id % num_pid_in_group) // group_size_m
## swizzle
num_pid_m_per_copy_chunk = M_PER_CHUNK // BLOCK_SIZE_M
chunk_offset = pid_m // (num_pid_m_per_copy_chunk * world_size)
rank_offset = pid_m % (num_pid_m_per_copy_chunk * world_size) // num_pid_m_per_copy_chunk
block_offset = pid_m % num_pid_m_per_copy_chunk
# swizzle rank offset, launch current rank firstly.
rank_offset = (rank_offset + rank) % world_size
pid_m = (rank_offset * M_per_rank + chunk_offset * M_PER_CHUNK + block_offset * BLOCK_SIZE_M) // BLOCK_SIZE_M
offs_am = pid_m * BLOCK_SIZE_M
offs_sig = offs_am // M_PER_CHUNK
offs_rank = pid_m // pid_m_per_rank
# Skip waiting local tensor as we pass it int kernel function as argument.
if offs_rank != rank:
token = dl.wait(barrier_ptr + offs_sig, 1, "sys", "acquire", waitValue=1)
A = dl.consume_token(A, token)
rm = (pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)) % M
rn = (pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)) % N
rk = tl.arange(0, BLOCK_SIZE_K)
rm = tl.max_contiguous(tl.multiple_of(rm, BLOCK_SIZE_M), BLOCK_SIZE_M)
rn = tl.max_contiguous(tl.multiple_of(rn, BLOCK_SIZE_N), BLOCK_SIZE_N)
if offs_rank == rank:
rm = rm % M_per_rank
A_BASE = localA + rm[:, None] * stride_am + rk[None, :] * stride_ak
else:
A_BASE = A + rm[:, None] * stride_am + rk[None, :] * stride_ak
B_BASE = B + rk[:, None] * stride_bk + rn[None, :] * stride_bn
tl.assume(pid_m > 0)
tl.assume(pid_n > 0)
loop_k = tl.cdiv(K, BLOCK_SIZE_K)
if not EVEN_K:
loop_k -= 1
acc = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=acc_dtype)
for k in range(0, loop_k):
a = tl.load(tl.multiple_of(A_BASE, (1, 16)))
b = tl.load(tl.multiple_of(B_BASE, (16, 1)))
acc += tl.dot(a, b)
A_BASE += BLOCK_SIZE_K * stride_ak
B_BASE += BLOCK_SIZE_K * stride_bk
if not EVEN_K:
k = loop_k
rk = k * BLOCK_SIZE_K + tl.arange(0, BLOCK_SIZE_K)
A_BASE = A + rm[:, None] * stride_am + rk[None, :] * stride_ak
B_BASE = B + rk[:, None] * stride_bk + rn[None, :] * stride_bn
A_BASE = tl.multiple_of(A_BASE, (1, 16))
B_BASE = tl.multiple_of(B_BASE, (16, 1))
a = tl.load(A_BASE, mask=rk[None, :] < K, other=0.0)
b = tl.load(B_BASE, mask=rk[:, None] < K, other=0.0)
acc += tl.dot(a, b)
c = acc.to(C.type.element_ty)
rm = (pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)) % M
rn = (pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)) % N
rm = tl.max_contiguous(tl.multiple_of(rm, BLOCK_SIZE_M), BLOCK_SIZE_M)
rn = tl.max_contiguous(tl.multiple_of(rn, BLOCK_SIZE_N), BLOCK_SIZE_N)
c_mask = (rm[:, None] < M) & (rn[None, :] < N)
C_ = C + rm[:, None] * stride_cm + rn[None, :] * stride_cn
tl.store(C_, c, c_mask)
To fully utilize the communication bandwidth of AMD GPUs, we use multiple streams for parallel processing and perform swizzling on the stream selection to enable AMD GPU links to work simultaneously.
def producer_ag_push_mode(
rank,
num_ranks,
local_tensor: torch.Tensor,
remote_tensor_buffers: List[torch.Tensor],
one: torch.Tensor,
M_PER_CHUNK: int,
ag_stream_pool: List[torch.cuda.Stream],
barrier_buffers: List[torch.Tensor],
):
M_per_rank, N = local_tensor.shape
chunk_num_per_rank = M_per_rank // M_PER_CHUNK
num_stream = len(ag_stream_pool)
rank_orders = [(rank + i) % num_ranks for i in range(num_ranks)]
data_elem_size = local_tensor.element_size()
barrier_elem_size = one.element_size()
for idx, remote_rank in enumerate(rank_orders):
if remote_rank == rank:
continue
for chunk_idx_intra_rank in range(chunk_num_per_rank):
# Chunk swizzle
chunk_pos = rank * chunk_num_per_rank + chunk_idx_intra_rank
stream_pos = idx % num_stream
ag_stream = ag_stream_pool[stream_pos]
M_dst_start_pos = rank * M_per_rank + chunk_idx_intra_rank * M_PER_CHUNK
M_src_start_pos = chunk_idx_intra_rank * M_PER_CHUNK
src_ptr = local_tensor.data_ptr() + M_src_start_pos * N * data_elem_size
dst_ptr = remote_tensor_buffers[remote_rank].data_ptr() + M_dst_start_pos * N * data_elem_size
nbytes = M_PER_CHUNK * N * data_elem_size
cp_res = hip.hipMemcpyAsync(
dst_ptr,
src_ptr,
nbytes,
hip.hipMemcpyKind.hipMemcpyDeviceToDeviceNoCU,
ag_stream.cuda_stream,
)
HIP_CHECK(cp_res)
# Set signal through copy-engine. This is a trick for AMD GPU.
cp_res = hip.hipMemcpyAsync(
barrier_buffers[remote_rank].data_ptr() + chunk_pos * barrier_elem_size,
one.data_ptr(),
barrier_elem_size,
hip.hipMemcpyKind.hipMemcpyDeviceToDeviceNoCU,
ag_stream.cuda_stream,
)
HIP_CHECK(cp_res)
AG GEMM Class
class triton_ag_gemm_intra_node(torch.nn.Module):
def __init__(
self,
tp_group: torch.distributed.ProcessGroup,
max_M: int,
N: int,
K: int,
M_PER_CHUNK: int,
input_dtype: torch.dtype,
output_dtype: torch.dtype,
):
self.tp_group = tp_group
self.rank: int = tp_group.rank()
self.world_size = tp_group.size()
self.max_M: int = max_M
self.N = N
self.K = K
self.M_PER_CHUNK = M_PER_CHUNK
self.input_dtype = input_dtype
self.output_dtype = output_dtype
# Use the auxiliary functions provided by Triton-distributed to construct the context required for AG-GEMM. This simplifies the code logic.
# The context mainly includes:
# (1) The globally symmetric memory required for AllGather;
# (2) The signals used for communication between AG and GEMM;
# (3) Streams.
self.ctx = create_ag_gemm_intra_node_context(
self.max_M,
self.N,
self.K,
self.input_dtype,
self.output_dtype,
self.rank,
self.world_size,
self.tp_group,
M_PER_CHUNK=M_PER_CHUNK,
)
def forward(self, input: torch.Tensor, # [local_M, K]
weight: torch.Tensor, # [local_N, K]
transed_weight: bool, # indicates whether weight already transposed
):
current_stream = torch.cuda.current_stream()
ctx = self.ctx
M = self.max_M
K = self.K
N_PER_RANK = weight.shape[1] if transed_weight else weight.shape[0]
# Create empty output buffer.
output = torch.zeros([M, N_PER_RANK], dtype=input.dtype, device=input.device) + 1.0
# Barrier before the current AG-GEMM operation. This step is necessary when running multiple rounds of computations.
torch.cuda.synchronize()
barrier_all_on_stream(self.rank, ctx.num_ranks, ctx.comm_buf_ptr, current_stream)
# Sync work streams.
for ag_stream in ctx.ag_streams:
ag_stream.wait_stream(current_stream)
# producer allgather
producer_ag_push_mode(ctx.rank, ctx.num_ranks, input, ctx.workspace_tensors, ctx.one, ctx.M_PER_CHUNK,
ctx.ag_streams, ctx.barrier_tensors)
torch.cuda.synchronize()
torch.distributed.barrier()
# consumer gemm
NUM_SMS = torch.cuda.get_device_properties(0).multi_processor_count
NUM_XCDS = 4
grid = lambda META: (min(
NUM_SMS,
triton.cdiv(M, META["BLOCK_SIZE_M"]) * triton.cdiv(N_PER_RANK, META["BLOCK_SIZE_N"]),
), )
full_input = ctx.workspace_tensors[ctx.rank][:M]
local_input = input
consumer_gemm_persistent_kernel[grid](
full_input,
local_input,
weight,
output,
M,
N_PER_RANK,
K,
full_input.stride(0),
full_input.stride(1),
weight.stride(1),
weight.stride(0),
output.stride(0),
output.stride(1),
ctx.rank,
ctx.num_ranks,
ctx.barrier_tensors[ctx.rank],
M_PER_CHUNK=ctx.M_PER_CHUNK,
NUM_SMS=NUM_SMS,
NUM_XCDS=NUM_XCDS,
)
return output
Benchmark
def torch_ag_gemm(
input: torch.Tensor, # [local_M, k]
weight: torch.Tensor, # [local_N, K]
transed_weight: bool,
bias: Optional[torch.Tensor],
TP_GROUP,
):
local_M, K = input.shape
world_size = TP_GROUP.size()
if transed_weight:
assert K == weight.shape[0]
else:
assert K == weight.shape[1]
weight = weight.T
assert input.device == weight.device
# AG + Gemm
full_input = torch.empty((local_M * world_size, K), dtype=input.dtype, device=input.device)
torch.distributed.all_gather_into_tensor(full_input, input, group=TP_GROUP)
output = torch.matmul(full_input, weight)
if bias:
output = output + bias
return output
def init():
RANK = int(os.environ.get("RANK", 0))
LOCAL_RANK = int(os.environ.get("LOCAL_RANK", 0))
WORLD_SIZE = int(os.environ.get("WORLD_SIZE", 1))
torch.cuda.set_device(LOCAL_RANK)
torch.distributed.init_process_group(
backend="nccl",
world_size=WORLD_SIZE,
rank=RANK,
timeout=datetime.timedelta(seconds=1800),
)
assert torch.distributed.is_initialized()
TP_GROUP = torch.distributed.new_group(ranks=list(range(WORLD_SIZE)), backend="nccl")
torch.distributed.barrier(TP_GROUP)
torch.use_deterministic_algorithms(False, warn_only=True)
torch.set_printoptions(precision=5)
torch.manual_seed(3 + RANK)
torch.cuda.manual_seed_all(3 + RANK)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
torch.backends.cuda.matmul.allow_tf32 = False
torch.backends.cuda.matmul.allow_fp16_reduced_precision_reduction = False
torch.backends.cuda.matmul.allow_bf16_reduced_precision_reduction = False
np.random.seed(3 + RANK)
torch.cuda.synchronize()
torch.distributed.barrier()
return RANK, LOCAL_RANK, WORLD_SIZE, TP_GROUP
def destroy():
torch.cuda.synchronize()
torch.distributed.barrier()
torch.distributed.destroy_process_group()
if __name__ == "__main__":
# init
RANK, LOCAL_RANK, WORLD_SIZE, TP_GROUP = init()
# NOTE: We should get device after process group init.
DEVICE = triton.runtime.driver.active.get_active_torch_device()
dtype = torch.float16
M = 8192
N = 11008
K = 4096
chunk_size = 256
local_M = M // WORLD_SIZE
local_N = N // WORLD_SIZE
input_dtype = dtype
output_dtype = input_dtype
atol = 1e-2
rtol = 1e-2
# Generate input and weight.
scale = TP_GROUP.rank() + 1
data_config = [((local_M, K), dtype, (0.01 * scale, 0), DEVICE), # input
((local_N, K), dtype, (0.01 * scale, 0), DEVICE), # weight
(None), # bias
]
generator = generate_data(data_config)
input, weight, bias = next(generator)
# torch
ref_out = torch_ag_gemm(input, weight, False, bias, TP_GROUP)
torch.cuda.synchronize()
torch.distributed.barrier()
# dist triton
dist_ag_gemm_op = triton_ag_gemm_intra_node(TP_GROUP, M, N, K, chunk_size, input_dtype, output_dtype)
tri_out = dist_ag_gemm_op.forward(input, weight, False)
if torch.allclose(tri_out, ref_out, atol=atol, rtol=rtol):
dist_print("✅ Triton and Torch match")
else:
dist_print(f"The maximum difference between torch and triton is {torch.max(torch.abs(tri_out - ref_out))}")
dist_print("❌ Triton and Torch differ")
# After all, destroy distributed process group.
destroy()